再谈拼音匹配系列目录:
第一节 即时匹配与语境
第二节 传统的字符串索引
第三节 拼音树(上)
第四节 拼音树(下)
第五节 杂项
所有内容的实现细节参见 PinIn
前言
最近这两三年以来,除去学校里做的零零散散的项目,我剩下的绝大部分时间都用在了 JECa 和 JECh 两个项目上。实话说 JECa 是一个比较传统的 Minecraft 项目:大量的代码用于描述世界交互,用户界面,数据存储,模组兼容等各种琐事,唯一能用算法解决的部分(CostList 的合并)却被我暴力破解了。而 JECh 则不同,他的目标只有一个:用最少的内存进行最快的搜索。尽管从下载量来看,JECh 相比起 JECa 根本不值一提,但是毫无疑问的是,我在这个项目上的技术积累要明显更多:其中用到的搜索引擎从一个套了各种缓存之后勉强能用的小玩意儿最后发展到了一个特性丰富而且性能可靠的系统。我最终将这个系统独立出来,也就是你们所看到的“PinIn”,一个处理各类拼音匹配问题的 Java 库。
如你所见,在这个破站上我相当多次的讨论过拼音匹配的问题,但是其中相当一部分已经被更高效的实现所替换,而另一部分则显得支离破碎。趁着这几天还有点时间,我打算把这套东西尽量完整的解释一遍,以至于他可能会是一个篇幅相当长的连载。尽管如此,要做到面面俱到几乎是不可能的。我所能做的就是抓重点部分,尽量完整的解释出来。另外,从本质上而言,这个系列也可以算作是 PinIn 的一个系统性说明。
至于我开这个坑的直接原因则是一个悲伤的故事:我前些日子去面了阿里,面试里提到了这个系统,当时这个系统还是基于字符串哈希缓存的即时搜索。这个面试官确实挺懂行,而且是个学院派。他跟我说的建议是考虑 NFA 或者字典树。当时我心里是郁闷的:我虽然不是科班毕业,但是这套东西我怎么说也是写了两年有余,哪里有提升空间我是再清楚不过了。但是一方面这套东西的实现本来就有些脱离经典算法,另一方面我我嘴又笨得要死,电话里完全说不清楚。这就使我更郁闷了。
郁闷归郁闷,我还是花了一个多礼拜重新研究了字符串相关的算法。这让我发现了另一个令人郁闷的事实:我的实时匹配本来就是基于 NFA + DFS 的,只不过我当时还不知道这么个名字。我心里一万头草泥马奔过,不过又暗自庆幸:虽说我没说清楚,但是不管怎么说,这个实现还算是在道上的。你也知道,在电话里用 5 分钟介绍一下 NFA 还要让人听明白,一方面难度巨大,另一方面,如果对方意识到了这就是 NFA 也同样尴尬:你可以想象一下,某一天跟人费了半天介绍了你新发现的排序算法,最后发现就是快排的一个变种,这仍然是十分尴尬的事件。
至于字典树(或者后缀树),我在那之前就认定了一个观点:对于多重匹配(多音字,缩写等),要用树来索引几乎是不可能的,因为连续的多重匹配必然需要大量的组合展开,这在复杂度上会造成灾难性的后果。当然,在真正实现之前,多数人对这个结论的感受是苍白的,而对各种传统索引的认可是根深蒂固的。我当时就写了一片长文讨论各类索引的局限性。不过,好在我当时没有直接发出去,因为在几个礼拜的反复琢磨后,我终于在字典树的基础上想到了这个被我称为“拼音树”的结构,同时也给我脑海里这个扎根已久的结论判了死刑。通过反复的优化,这个结构在性能和内存占用上都取得了相当可观的结果。至于这部分的内容,我在之后还会细说。
我很少在写文章时填充这么长的前言。这次我说了这么多废话,很大程度上是因为这个狗血的小故事和这个项目的开发有着异常紧密的联系。我想能看到这篇文章的人很少是来研究技术的——我作为一个扯淡十级的菜鸡,真正写起技术文章来根本就是乏善可陈。不过如果你真的是奔着技术内容来的,那不好意思,我们现在就开始说正事。
使用情景
这个项目的开发动机是在 Minecraft 中使用拼音来搜索物品。在较为复杂的游戏环境中,需要搜索的物品大约有 40k 个,其中涉及到的词条我们暂且认为小于 200k 个。对所有词条的匹配需要实时执行,并且避免造成肉眼可见的卡顿。也就是说,对于 200k 个词条 (约合 2M 个单字),耗时需要在 10ms 一下。与此同时,我希望拼音匹配的逻辑能尽可能灵活,这也就是拼音搜索的万恶之源。我这里直接引用项目介绍中的描述:
对于“中国”,可以允许的搜索串包括但不限于“中国”,“中guo”,“zhongguo”,“zhong国”,“zhong1国”,“zh1国”,“zh国”。 基于模糊音设置,还允许“zong国”,“z国”等。
除此之外,索引串可能包含中英文混合的内容,对于这部分内容,对汉字进行拼音匹配,并对英文进行原文匹配。对于以上的要求,如果可以不使用索引,完全依赖即时匹配当然是极好的,如果不得不使用索引的话,内存消耗自然是越小越好。对于一台可以启动这个规模游戏的电脑,内存可以假设在 4GB 以上。对于这样的环境,用于索引这 200k 个词条的结构如果内存占用大于 500MB 就显得有些不切实际了。
实时匹配
在这个系列的第一篇,我想用剩下的篇幅来谈实时匹配。首先是因为它不像各类索引结构那样又臭又长,其次,尽管在索引中对匹配性能的要求并没有在实时匹配中这么苛刻,但是其中的匹配逻辑仍然是拼音索引的基石,我没法对他视而不见。
这是一个比较典型的 NFA 模型,将我们的拼音串,举个例子,“zhongguo”作为状态机,而汉字串“中国”则作为输入。对于状态机,我们先使用偏移量将他进行标号:
1
2
z h o n g g u o
0 1 2 3 4 5 6 7 8
每次匹配起始于状态 0。输入”中”时,通过调用相关的匹配逻辑,我们可以知道状态可以转换到 2(匹配声母)或者 5(匹配全拼)。对于两个可选状态,我们对其分别输入“国”。对于状态 2,由于不存在符合拼法的组合,匹配失败,而对于状态 5,可以转换到状态 6 或者状态 8。当任何一条路径可以抵达终止状态(即状态 8)时,则判定汉字和中文匹配。这个状态机的实现其实相当简单:直接使用递归进行深度优先搜索即可。对于我们目前的使用情景,Java 默认的调用栈就足够我们递归匹配完整个句子,而在性能上也相当可靠。
这个算法的难点反而转移到了单个文字的匹配:我们如何快速的判定“中”可以匹配“zh”或者“zhong”呢?核心思路同样非常简单:一个拼音通常分为三个部分,即声母,韵母和声调,在代码中我们将其统称为音素 Phoneme。对于拼音“zhong1”而言,就是“zh”,“ong”和“1”。对于每个音素我们进行基于偏移量的全文匹配:首先它可以全文匹配“zh”,这决定了状态 2 是一个可以接受的状态。其次它可以在偏移两位的条件下匹配“ong”,这决定了状态 5 也是可以接受的状态。至于“1”,无法匹配,所以无法转移到状态 6。
这个逻辑的核心的确不复杂,但是考虑到各种简拼(“zh1”),多音字(“zhong4”)和模糊音(“zong”)就有些麻烦了。这里我们不再过多讨论简拼组合:实际实现中使用了一个小技巧来避开遍历各种组合,但是可圈可点的地方并不多。但是在另一方面,对于分割音素,多音字以及生成模糊音,我们需要一个可靠的缓存来避免反复劳动。这个缓存的结构最好和键盘无关,因为不同的键盘需要共享同样的缓存结构。举个例子,形如下面的代码是不允许的:
1
2
3
if (phoneme.equals("zh") && fuzzy) {
return match(input, "zh") || match(input, "z");
}
这样做的原因是在汉语拼音中“zh”映射到键位是“zh”,而在其他键盘中的键位则是完全不同的。对于不同的键盘,将模糊音分别硬编码会产生相当高的维护成本和错误风险。取而代之的是,我们根据模糊音设置,将备选的音素在运行时根据键盘设置一并写入匹配列表,就可以比较轻松地完成这个任务。举个例子,在构造音素“zh”之初,我们就直接让其同时匹配当前键盘下“zh”和“z”的拼法,而不是通过硬编码逻辑令其强行兼容,即可轻松解决这个问题。对于多音字,我们也如法炮制,就获得了下图的结构:
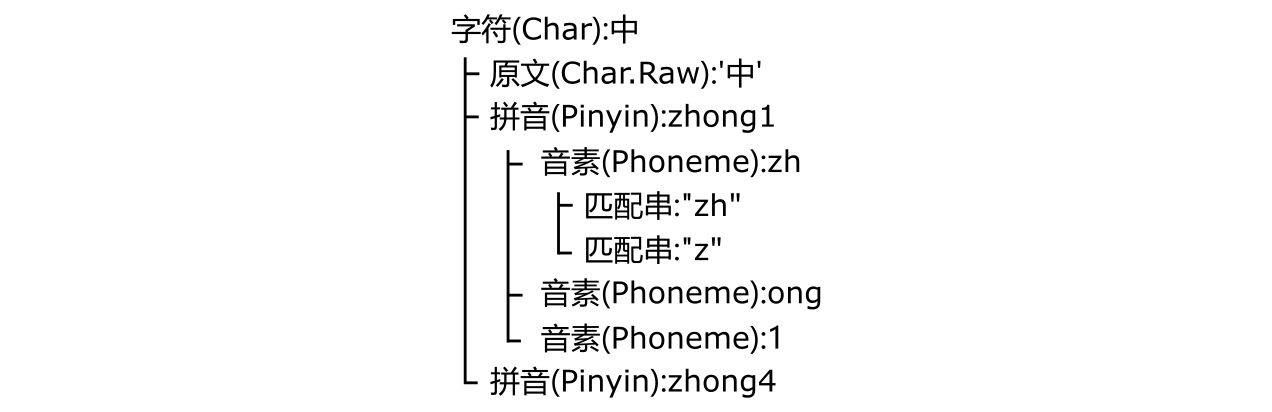
图中的Char,Char.Raw,Pinyin,Phoneme均实现了Element接口,可以独立完成匹配。对于上层对象而言,他们只需要将匹配的输入直接转交到下层对象,并将结果合并。而最终,匹配的逻辑将会落实到上图中匹配串的全文匹配上。
如你所见,对于任何一个汉字,这个模板都将其拆分到了最小的拼写单元。在执行匹配的时候,我们不需要将性能花在各种拆分的操作上,从而显著提升了匹配速度。你可能会担心对于所有汉字,维护一份如此细分的模板会占用大量的内存,但是你大可不必为此操心。一方面汉字虽多,真正在文本中出现过的常常是其中的一小部分,此外,所有 Char 以下层级的对象均是共享的,我们不必为此耗费额外的内存。
语境系统
提到共享对象,就不可避免地要提到语境系统。我们这里先将一组键盘和模糊音设置称作一个语境。如你所见,对于不同的语境,拼音的拼法通常是不同的。这也就意味着在不同语境之间,拼音和音素是无法共享的。由于这样的绑定关系,语境(PinIn 对象)不仅可以存储配置,同时被用于维护特定语境下的共享对象,这也就保证了不同语境下的共享对象之间是分离的。当我们需要同时在多个语境下进行匹配时,我们只需要使用多个语境对象,即可轻松的维护多组共享对象。
你可能要问了,既然共享对象和语境是绑定的,当语境的配置改变(比如切换键盘)时我们怎么处理呢?这里有两个直观的解决方案:1)直接规定每个语境的配置不可更改,需要改变配置时必须建立新的语境对象;2)在语境的配置改变时重新构建所有共享对象。这两个方案自然是安全可靠的,但是有一个明显的弊端:在语境切换时必然产生缓存重建的开销。这不仅意味着 Char,Pinyin 和 Phoneme 的重建,而且要求任何引用了上述对象的结构(比如索引)全部需要重建。
上述两个方案造成性能开销的根源很简单:在语境改变时,任何指向共享对象的引用都会无效化。因此,如果我们重用原有的对象,在配置改变时保持原有的引用有效,即可最小化重建缓存的开销。在实现上,这一逻辑也很简单:我们只需要在配置改变时根据当前的语境向已有的共享对象中重新填充内容,即可在不改变共享对象引用的条件下将共享对象切换到当前语境。基于这一机制,我们可以使用极小的消耗,在大部分场景中任意切换语境。
小结
这一节中我们讨论了 PinIn 中使用的核心概念——语境,同时简单介绍了实时匹配的实现逻辑。在下面的章节中,我们将会讨论基于索引的匹配逻辑。不过先别急,在此之前我们会先讨论已有的字符串索引结构。我们不仅会解释为何传统的字符串索引不适用于拼音搜索的场景,同样还会讨论其中有哪些我们可以借鉴的思路。
这个坑填起来似乎比我想象中艰难不少,一方面因为我一天中还要学车和给我妈做饭(是的),另一方面我还要反复修改表达来保证文中的解释通俗易懂。但是不管怎么说,这个坑我还是会填下去的,回见。
若非特殊注明,文章均为博主原创,通过 CC 4.0 BY License 授权转载