再谈拼音匹配系列目录:
第一节 即时匹配与语境
第二节 传统的字符串索引
第三节 拼音树(上)
第四节 拼音树(下)
第五节 杂项
所有内容的实现细节参见 PinIn
前言
今天我们将要迎来这段连载的核心部分——拼音树。简而言之,他也是一种后缀树的变种。类似于传统后缀树树的使用场景,拼音树同样被用来对大批量字符串执行子串匹配。唯一不同的是,这里我们使用拼音子串来匹配汉字原文。
传统索引
说到这里你可能就要问了,我们之前刚刚介绍了那么多用于子串匹配的索引结构,难道不可以直接使用么?一个非常直观的解决方案就是将一个汉字字符串转化成他对应的所有拼法,再用前文给出的索引搜索拼音串。这并不是不可以,但是有一个显而易见的缺陷:在多种拼法的基础上进行排列组合,对于长串而言带来的组合数几乎是灾难性的。举个例子,“中”有 4 种拼法,“国”也有 4 种拼法,那么对于“中国”,则有 16 种拼法,而对于“中国中国”,则有 256 种拼法。一旦使用这种索引方式,内存消耗几乎是天文数字。我们暂且把这一困境称作“组合困境”。
当我们用字典树建字符串索引时,它其实是一个“英文原文->英文原文”的搜索。对于这样的关系,我们没有必要区分正排索引与倒排索引,因为他们在本质上是一致的。而对于拼音匹配,它描述的是“英文拼音->汉字原文”的搜索关系,这时倒排索引和正牌索引就产生区别了。更加麻烦的是,不管汉字对应拼音或是拼音对应汉字都是一对多的关系,所以我们不可能使用一对一的预处理来对这一关系进行简化。在这一场景下,我们要么对汉字原文建立索引,即正排索引,要么对英文拼音建立索引,即倒排索引。如果我们进行倒排索引,那么势必会遭遇前文所述的组合困境,但是当我们使用正排索引,实现拼音匹配必然要对传统的索引结构加以改动。
胶水层
这样看来,倒排索引似乎是山穷水尽了,但是先别急着下定论,在后文中他还会重获新生。我们这里着重来讨论正排索引。首先需要阐明的是,使用传统字符串索引结构生成的正排索引等效于对汉字原文生成的索引。既然绝大部分字符串索引都依赖于字典树,那么我们能否通过魔改字典树,使其适用于拼音搜索呢?答案是肯定的。我们只需要修改层间跳转的逻辑,使其兼容拼音匹配,即可将字典树用于拼音匹配。我们暂且将这一部分逻辑称作胶水层。
遍历法
下图给出了存储有“中国”,“中箭”和“中间”三个字符串的字典树。基于这个结构,我们有一种极为粗糙而直接的匹配逻辑,即基于拼音遍历匹配所有边。举个例子,当我们搜索“zhongj”,我们从根节点出发,匹配字符“中”,可得搜索串可以跳转到状态 2 和状态 5。在状态 2,剩余搜索串“ongj”无法匹配任何一条边。在状态 5,我们在匹配“间”和“箭”时可以完成匹配,而在匹配“国”时无法匹配。最后可得搜索串“zhongj”只能在索引中匹配“中间”和“中箭”。这一胶水层的策略我们暂且称作“遍历法”。尽管这遍历法相当繁琐,但是相比起用搜索串遍历匹配所有索引串,他仍然具有性能优势:在所有索引串中,对于边“中”,我们只需要执行一次匹配,而在遍历匹配时则需要匹配多次。

1
2
z h o n g j
0 1 2 3 4 5 6
字典树对于字符串逻辑具有性能优势的一大原因是它可以避免重复执行匹配逻辑:当我们在字典树中从一个节点转移到另一个节点时,我们实际上在所有索引串中执行了一次状态的移动。因此,无论有多少个索引串,字典树只需要执行一次搜索就可以获得所有结果(合并加速)。即使使用效率底下的遍历法,我们也能多少从这一关系中获得性能提升。而在另一方面,对基于哈希表的字典树实现,程序可以在常数时间内决定跳转的边。因此,无论字典树中的节点有多少子节点,不同于遍历匹配,我们可以认为字典树永远在执行一次匹配后就决定了跳转方向(跳转加速)。对于遍历法而言,这一优势自然荡然无存。
子树法
对字典树而言,合并加速与跳转加速都在节点密集的区域效果明显。不同的是,合并加速在一个节点表示多个索引串时生效,而跳转加速在存在大量子节点时生效。使用遍历法时,我们放弃了跳转加速,这自然会显著影响到搜索性能。那么是否存在遍历法以外的胶水层实现让我们重新获得跳转加速呢?你也猜到了,既然我已经这么问了,那自然是有的。
在前文中我们也说过了,倒排索引具有相当可观的性能,它的核心缺陷就是组合困境。而在我们眼下的胶水问题中,永远只需要面对一层索引,也就意味着组合困境并不存在。因此,我们完全可以使用局部的倒排索引来充当高效的胶水层。使用局部的倒排索引就相当于在原先的树结构中局部插入一些子树,因此这一策略被称作子树法。
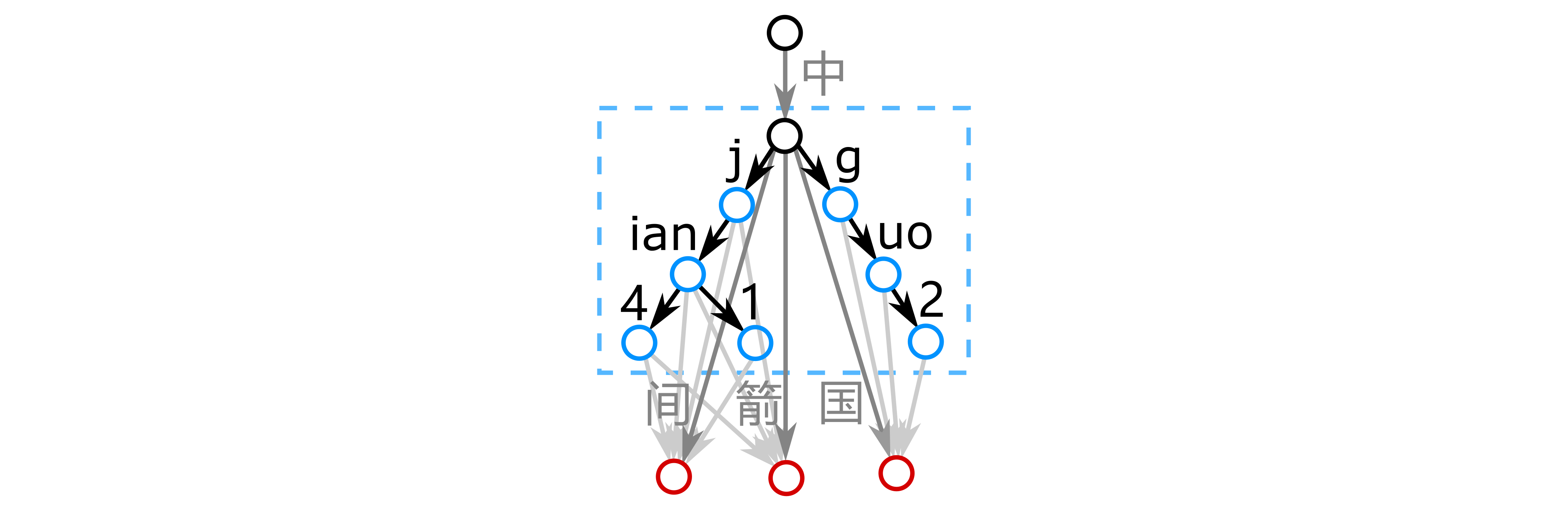
对于之前的字典树,上图给出了子树法的构建细节:图中蓝色框中即上文提到的“子树”结构:我们在索引串的两层之间插入了一部分由搜索串构成的字典树。在执行搜索时,这个由子树构成的胶水层可以将我们直接引导至搜索串所对应的节点,从而避开遍历搜索。图中深灰色的箭头代表着字典树原先的连接关系,而浅灰色箭头代表着从子树节点到下一层节点的连接关系。你可能已经注意到了,算上子树节点,下一层节点实际上被多个节点引用,而这是不符合树“每一个非根节点有且只有一个父节点”的规定的。也就是说,子树法的本质是在局部引入了一个基于字典树的图结构,这也恰恰也完美描述了前文提到的“双向多对多”的关系:不同于树结构,在这个局部图中,每个字符可以被多个拼音引用,而每个拼音也可以引用多个字符。
子树的使用给搜索性能带来了无可置疑的提升,但是它也带来了不可忽视的内存消耗。我们基于前文的假设,认为文本中的每一个字符对应一个节点。如果我们使用子树法加速搜索,每个节点将不可避免的多维护一个树结构以及相当多的引用关系。这个树的大小可能因节点而异,但是整体上至少会使整个数据结构的内存占用翻倍,甚至增加数倍。尽管相比起全局层面的倒排索引,子树法在提供可观性能的同时,将内存消耗限制在了一个可控的范围,但是这个级别的内存占用将使它无法适用于相当多的工程场景。如果你对性能有着极端的追求,你可以选择这一策略,但是对于大部分场景,我们更在意速度于内存消耗的平衡,所以大可不必这么激进。
混合法
上文给出了两种理想化的胶水策略,一种轻速度而重内存,一种重速度而轻内存。而在实际操作中,一个核心思想就是将内存用在刀刃上。基于这一策略,我们可以对此稍做优化:在子节点少的节点中使用遍历法,在子节点多的节点中使用子树法。对于子树法,我们也可以通过只生成子树的第一层节点来简化它的结构,从而在牺牲少量性能的条件下显著缩减内存占用。这就是实际代码中所使用的胶水策略。
小结
在这一节中我们给出了拼音树的核心思路:在字典树中插入胶水层使其适用于拼音搜索的场景。尽管我们在局部使用了倒排索引的结构,但是请注意,这在整体层面上仍然是正排索引。他和倒排索引有着本质上的区别:在执行搜索时,倒排索引只需要沿着一条路径即可完成搜索,而正排索引并不保证匹配的索引串出现在同一分支上,所以常常需要访问大量分支来完成搜索。这也就是正排索引在根本上的性能瓶颈:传统的字典树本质上是 DFA,而基于胶水层搜索的拼音树本质上是 NFA。虽然在理论上 NFA 可以转变为 DFA,但是我们并不能承受其中涉及到的内存开支。
到此为止,拼音树的雏形已经基本浮现了。基于这样的结构,我们已经可以实现空间复杂度和性能都相当可观的拼音索引了。尽管如此,他在内存占用上距离工业级的应用还稍有距离:绝大部分输入法在使用大于 1 MB 的词库时仍能保证 10 MB 以下的内存占用。向着这个目标,我们下一节中将讨论更多的技巧来优化它的内存占用。除此之外,下一节还会讨论更多的实现细节与设计思路。回见。
若非特殊注明,文章均为博主原创,通过 CC 4.0 BY License 授权转载